How Retrieval-Augmented Generation (RAG) Helps Reduce AI Hallucinations
Written By
Published On
Read Time

Retrieval-Augmented Generation (RAG) represents a significant advancement in the field of artificial intelligence (AI), particularly in enhancing the capabilities of large language models (LLMs). This innovative AI framework retrieves data from external knowledge sources to augment the responses of LLMs, thereby improving their accuracy and relevance. RAG has become increasingly important in various applications, including chatbots, search engines, and knowledge engines, where up-to-date and accurate information is crucial.
What is Retrieval-Augmented Generation (RAG)?
Retrieval-Augmented Generation (RAG) is a cutting-edge approach in artificial intelligence, particularly in the realm of natural language processing. This technique enhances the capabilities of large language models (LLMs) like chatbots, making them more accurate and up-to-date. RAG works by pulling in data from external sources, which helps fill in gaps in the model's knowledge base, especially for tasks requiring current information or those outside the initial training data. Building a RAG pipeline can further enhance your AI’s capabilities by automating the retrieval of external data and integrating it seamlessly into your model.
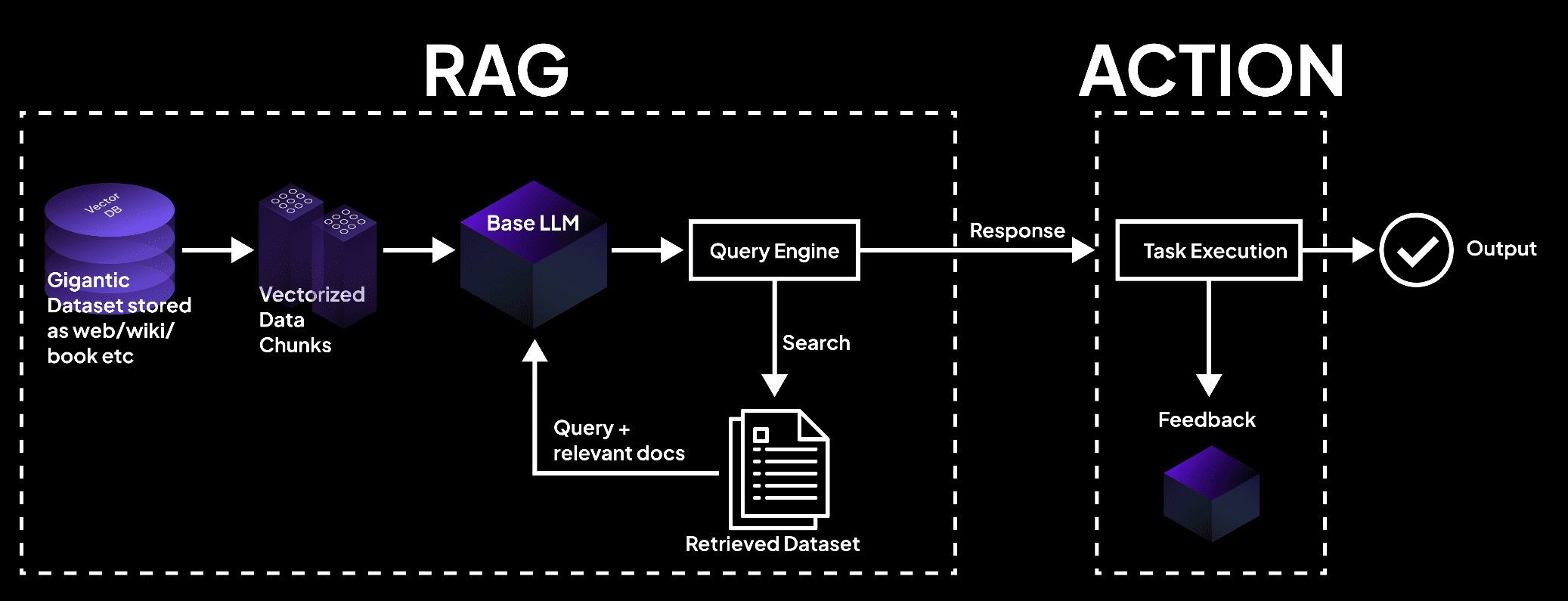
How Does Retrieval-Augmented Generation Work?
Retrieval-Augmented Generation (RAG) is a sophisticated technique in artificial intelligence that significantly enhances the performance of large language models (LLMs). This method involves integrating external data sources into the AI's response process, ensuring more accurate, relevant, and up-to-date outputs. Let's delve into the workings of RAG and understand its mechanism in detail.
The Core Mechanism of RAG
Data Retrieval: At its core, RAG starts by retrieving data from various external sources. This could include databases, online resources, application programming interfaces (APIs), and document repositories. The aim is to access current and specific information that the LLM was not initially trained on.
Prompt Analysis and Summarization: When a user inputs a query or prompt, RAG first analyzes and summarizes this prompt. It uses keywords or semantic analysis to understand the essence of the query.
Searching for Relevant Information: The summarized prompt is then used as a basis to search for relevant external data. This step is crucial as it determines the quality and relevance of the information that will be used to augment the LLM's response.
Sorting and Synthesizing Data: Once relevant data is retrieved, it's sorted based on its applicability to the query. The LLM then synthesizes this data with its pre-existing knowledge base. This synthesis is a delicate process where the model combines new information with what it has already learned, ensuring a coherent and contextually appropriate response.
How to Use RAG with Large Language Models (LLMs)?

Integrating Retrieval-Augmented Generation (RAG) with Large Language Models (LLMs) like ChatGPT or Google Bard is a transformative approach in the field of artificial intelligence. This integration significantly enhances the capabilities of LLMs, making them more accurate, relevant, and up-to-date. Let's explore the step-by-step process of how RAG can be effectively used with LLMs.
Step 1: Identifying the Need for External Data Retrieval
Recognizing Limitations of LLMs: The first step is to understand the limitations of LLMs in terms of their training data. LLMs might not have information on recent developments or specific domain knowledge outside their training set.
Determining Use Cases: Identify scenarios where RAG can be most beneficial, such as in tasks requiring up-to-date information or specialized knowledge.
Step 2: Setting Up Data Retrieval Mechanisms
Selecting Data Sources: Choose relevant external sources like online databases, APIs, or document repositories that can provide the needed information.
Building Retrieval Infrastructure: Develop or integrate a system capable of querying these sources based on the prompts received from the LLM.
Step 3: Prompt Analysis and Data Retrieval
Analyzing User Prompts: When a user interacts with the LLM, the system first analyzes the prompt to understand its context and requirements.
Retrieving Relevant Information: Based on this analysis, the RAG system retrieves pertinent information from the selected external sources.
Step 4: Data Integration and Response Generation
Synthesizing Information: The retrieved data is then synthesized with the LLM’s pre-existing knowledge. This step is crucial as it combines new external data with the LLM's trained data to form a comprehensive response.
Generating Responses: The LLM, now augmented with fresh and relevant information, generates a response that is more accurate, detailed, and contextually appropriate.
Step 5: Continuous Learning and Updating
Feedback Loop: Implement a feedback mechanism where the LLM learns from the new data and responses, allowing for continuous improvement in accuracy and relevance.
Regular Updates: Ensure the external data sources are regularly updated so that the RAG system continually provides the most current information.
Practical Considerations in Using RAG with LLMs
Customization for Specific Domains: Tailor the RAG systems with fine-tuning for specific industries or domains to enhance the LLM’s performance in those areas.
Balancing Data Sources: Carefully balance the reliance on external data with the LLM’s original training to maintain the integrity and style of the model’s responses.
Ensuring Data Quality: Verify the reliability and accuracy of external data sources to prevent the incorporation of erroneous information.
Benefits of Using RAG with LLMs
Enhanced Accuracy and Relevance: RAG significantly improves the accuracy and relevance of LLM responses, especially in scenarios requiring current knowledge or specialized information.
Reduced AI Hallucinations: By grounding responses in real-world data, RAG reduces the chances of LLMs generating incorrect or misleading information.
Adaptability and Flexibility: RAG allows LLMs to adapt to new information and domains quickly, making them more versatile and powerful tools.
Retrieval-Augmented Generation vs. Semantic Search
Understanding the distinction between Retrieval-Augmented Generation (RAG) and Semantic Search is crucial in the realm of artificial intelligence and natural language processing. Both technologies significantly enhance the way information is processed and presented, but they operate differently and serve distinct purposes.
What is Retrieval-Augmented Generation (RAG)?
Retrieval-Augmented Generation is an advanced AI technique used to enhance the capabilities of Large Language Models (LLMs). It involves integrating external data into the AI's response process. This integration allows LLMs to provide more accurate, relevant, and up-to-date responses by supplementing their pre-existing knowledge with information retrieved from external sources.
Data Integration: RAG pulls data from various external sources like databases, online resources, and document repositories.
Enhancing LLMs: It improves the performance of LLMs by providing them with additional, often more current, information.
Dynamic Responses: RAG enables LLMs to generate responses that are not only based on their training data but also supplemented with the latest external information.
What is Semantic Search?
Semantic Search, on the other hand, refers to the process of understanding the intent and contextual meaning behind a user's query. Unlike traditional keyword-based search, which focuses on matching exact words, semantic search delves into the nuances of language to interpret the intent and contextual meaning behind a search query.
Understanding Intent: It goes beyond keywords to understand the user's intent and the context of the query.
Deep Content Analysis: Semantic search analyzes the meaning of the words in the query and the content it searches through, leading to more accurate and relevant results.
Enhanced User Experience: By understanding the nuances of language, semantic search provides results that are more aligned with what the user is actually looking for.
Comparing RAG and Semantic Search
Purpose and Function: RAG is primarily focused on enhancing the output of LLMs by integrating external data, while semantic search is concerned with improving search results by understanding the deeper meaning of queries.
Data Utilization: RAG actively retrieves and synthesizes external data to improve response quality, whereas semantic search leverages the understanding of language and context within the existing data.
Application Areas: RAG is widely used in applications involving LLMs like chatbots and virtual assistants, enhancing their responses. Semantic search is predominantly used in search engines and information retrieval systems to provide more relevant search results.
Technological Approach: While RAG combines data retrieval with AI-generated responses, semantic search employs natural language understanding to interpret and process queries.
Synergy in Application
In practice, RAG and semantic search can complement each other. For instance, a system using RAG to enhance its LLMs could also employ semantic search to better understand and process user queries. This combination would not only provide responses that are contextually relevant (thanks to semantic search) but also enriched with the latest information (through RAG).
Benefits of Retrieval-Augmented Generation
Retrieval-Augmented Generation (RAG) has emerged as a groundbreaking approach in the field of artificial intelligence, particularly in enhancing the capabilities of Large Language Models (LLMs). This innovative technique brings a host of benefits that address the limitations of traditional LLMs and open up new possibilities for AI applications. Let's explore these benefits in detail.
1. Access to Current and Comprehensive Information
Up-to-Date Responses: One of the primary advantages of RAG is its ability to provide information that is current and updated. By retrieving data from external sources, RAG ensures that the responses generated by LLMs are not just based on their training data but also include the latest developments and information.
Comprehensive Knowledge Base: RAG extends the knowledge base of LLMs beyond their initial training data, allowing them to pull in a wide range of information from various external sources, thus offering more comprehensive responses.
2. Enhanced Accuracy and Relevance
Reduction in AI Hallucinations: Traditional LLMs can sometimes generate plausible but incorrect information, known as "AI hallucinations." RAG mitigates this by grounding the LLM's responses in real-world, verifiable data, thereby enhancing the accuracy of the information provided.
Contextually Relevant Responses: By integrating external data relevant to the user's query, RAG ensures that the responses are not only accurate but also contextually relevant, making them more useful and applicable.
3. Increased User Trust and Transparency
Trustworthy Responses: The ability of RAG to provide sourced and current information increases user trust in AI systems. Users can rely on the accuracy and relevance of the responses they receive.
Transparency: RAG often includes citations or sources of the external data used, which adds a layer of transparency. Users can verify the information themselves, further enhancing their trust in the system.
4. Cost and Resource Efficiency
Reduced Need for Continuous Retraining: Traditional LLMs require frequent retraining to stay current, which can be resource-intensive. RAG reduces this need by supplementing the LLM's knowledge base with real-time data extraction, thus saving on computational and financial resources.
Efficient Data Utilization: RAG allows for the efficient use of existing data sources, reducing the need to create or acquire large datasets for training purposes.
5. Versatility and Customization
Adaptability to Various Domains: RAG can be tailored to specific industries or domains, making it a versatile tool for a wide range of applications, from healthcare to customer service.
Customizable Responses: The ability to pull in data from domain-specific sources means that RAG can be customized to provide responses that are highly relevant to specific fields or areas of interest.
6. Improved User Experience
Interactive and Dynamic Interactions: RAG enhances the interactivity of LLMs, making conversations with AI systems more dynamic and engaging.
Meeting User Expectations: By providing accurate, relevant, and current information, RAG meets and often exceeds user expectations, leading to a better overall user experience.
Challenges of Retrieval-Augmented Generation
While Retrieval-Augmented Generation (RAG) offers significant advancements in the field of artificial intelligence, particularly in enhancing Large Language Models (LLMs), it is not without its challenges. Understanding these challenges is crucial for the effective implementation and further development of RAG systems. Let's delve into some of the key challenges associated with RAG.
1. Complexity in Integration and Implementation
Technical Complexity: Integrating RAG with existing LLMs involves complex technical processes. It requires a sophisticated understanding of both natural language processing and data retrieval systems.
System Integration: Seamlessly combining RAG with LLMs to ensure efficient data retrieval and synthesis can be challenging, especially when dealing with diverse data sources and formats.
2. Ensuring Data Quality and Relevance
Data Accuracy: One of the significant challenges is ensuring the accuracy of the data retrieved from external sources. Inaccurate or misleading data can lead to incorrect responses from the LLM.
Relevance of Retrieved Data: The system must be capable of discerning the relevance of the retrieved data to the specific query, which requires advanced algorithms and fine-tuning.
3. Balancing Timeliness with Depth of Information
Real-Time Data Retrieval: Ensuring that the data retrieved is not only relevant but also current, poses a challenge, especially in rapidly changing fields.
Depth vs. Timeliness: Striking the right balance between providing in-depth, comprehensive responses and ensuring the information is up-to-date is a complex task.
4. Computational and Resource Constraints
Resource Intensity: The process of retrieving and processing large volumes of external data in real-time can be resource-intensive, requiring significant computational power and storage.
Scalability Issues: As the scope of RAG expands, scaling the system to handle larger datasets and more complex queries can be challenging.
5. Handling Ambiguity and Contextual Nuances
Understanding Context: RAG systems must be adept at understanding the context and nuances of user queries, which can be particularly challenging in languages with high levels of ambiguity.
Contextual Data Integration: Integrating external data in a way that accurately reflects the context of the query requires advanced understanding of both the language and the subject matter.
6. Ethical and Privacy Concerns
Data Privacy: Retrieving data from external sources raises concerns about user privacy and data security, especially when dealing with sensitive information.
Ethical Use of Data: Ensuring that the data is used ethically and responsibly, particularly in applications that have significant societal impacts, is a critical challenge.
7. Continuous Learning and Adaptation
Updating Knowledge Bases: Continuously updating the knowledge bases to include the latest information without compromising the system's stability can be challenging.
Adapting to New Domains: Adapting RAG systems to new domains or subject areas requires ongoing learning and fine-tuning.
Practical Applications and Use Cases of RAG
Retrieval-Augmented Generation (RAG) has rapidly become a transformative force in the field of artificial intelligence, offering innovative solutions across various industries. By integrating external data into Large Language Models (LLMs), RAG significantly enhances the capabilities of AI systems in providing accurate, relevant, and timely responses. Let's explore some of the practical applications and use cases where RAG is making a substantial impact.
1. Enhanced Customer Support
Chatbots and Virtual Assistants: RAG is instrumental in improving the performance of chatbots and virtual assistants. By accessing up-to-date information from external sources, these tools can provide more accurate and relevant responses to customer inquiries, leading to improved customer satisfaction and engagement.
Automated Support Systems: In customer service, RAG enables automated systems to provide detailed and current answers to specific queries, reducing the reliance on human support and increasing efficiency.
2. Advanced Search Engines
Improving Search Relevance: RAG can be integrated into search engines to enhance their ability to provide contextually relevant and comprehensive search results. This is particularly useful in academic research or in industries where staying current with the latest information is crucial.
Data Retrieval for Complex Queries: For complex or nuanced queries, RAG-equipped search engines can delve into a vast array of external sources, ensuring that the most relevant and comprehensive information is retrieved.
3. Healthcare and Medical Research
Up-to-Date Medical Information: In healthcare, RAG can be used to provide the latest medical research and treatment information, assisting healthcare professionals in staying informed about recent developments.
Patient Care and Diagnosis: AI systems equipped with RAG can assist in diagnosing diseases by retrieving and analyzing the latest research and clinical data, leading to more informed and accurate patient care.
4. Financial and Market Analysis
Real-Time Market Data: In the financial sector, RAG can be used to analyze market trends and provide real-time financial insights by pulling in the latest market data and news.
Risk Assessment and Management: RAG can enhance risk assessment models by incorporating the most current data, helping financial institutions make more informed decisions.
5. Personalized Learning and Education
Tailored Educational Content: In education, RAG can be used to create personalized learning experiences by retrieving and integrating information that aligns with a student's learning pace and interests.
Up-to-Date Educational Resources: RAG can ensure that educational content, especially in rapidly evolving fields, remains current and relevant.
6. Content Creation and Media
Automated Journalism: In media, RAG can assist in automated journalism by gathering and synthesizing the latest news and information from various sources, enabling quicker and more comprehensive reporting.
Creative Writing Assistance: RAG can aid in creative writing by providing writers with inspiration and information drawn from a wide range of sources.
7. Legal and Compliance
Legal Research: RAG can streamline legal research by quickly retrieving relevant case laws, statutes, and legal writings, saving time and enhancing the thoroughness of legal analysis.
Compliance Monitoring: In regulatory compliance, RAG can be used to monitor and analyze the latest regulations and compliance requirements across different jurisdictions.
8. E-commerce and Retail
Product Recommendations: RAG can enhance the accuracy of product recommendations in e-commerce by analyzing up-to-date customer data and market trends.
Customer Insights: Retailers can use RAG to gain insights into customer preferences and market dynamics, leading to better inventory management and marketing strategies.
What Challenges Does the Retrieval-Augmented Generation Approach Solve?
Retrieval-Augmented Generation (RAG) is a groundbreaking approach in artificial intelligence that addresses several key challenges faced by Large Language Models (LLMs) and other AI systems. By integrating external data sources into the response generation process, RAG significantly enhances the capabilities of these models. Let's explore the specific challenges that RAG effectively addresses.
Problem 1: LLM Models Do Not Know Your Data
One of the fundamental challenges with Large Language Models (LLMs) is their inherent limitation in knowledge scope. LLMs, such as OpenAI's GPT models, are trained on vast datasets that encompass a wide range of general knowledge. However, they often lack specific, up-to-date, or proprietary information about individual organizations or niche domains.
Limited to Training Data: LLMs are restricted to the information available in their training datasets. If these datasets do not include specific or recent information about a particular subject, the LLM will not be able to provide accurate responses regarding that subject.
Lack of Personalization: Traditional LLMs cannot inherently understand or incorporate an organization's unique data, such as internal reports, specific research, or real-time data, into their responses.
Problem 2: AI Applications Must Leverage Custom Data to Be Effective
For AI applications to be truly effective and deliver value, they must be able to leverage custom data that is specific to the user's context or the organization's domain. This is particularly crucial in fields where specialized knowledge is key, or where information is rapidly evolving.
Need for Domain-Specific Responses: In many professional fields like law, medicine, or finance, users require responses that are not just generally accurate but also specifically relevant to their domain.
Dynamic Information Requirements: In sectors where information changes rapidly, such as news, market trends, or technological advancements, AI applications need to access the most current data to provide valid responses.
Solution: Retrieval Augmentation Is Now an Industry Standard
Retrieval-Augmented Generation (RAG) has rapidly evolved to become an industry standard in the realm of artificial intelligence and natural language processing. This innovative approach, which enhances the capabilities of Large Language Models (LLMs) by integrating external data sources, is now widely recognized and adopted across various sectors. Let's delve into why RAG has achieved this status and its significance in the industry.
Emergence as a Standard Practice
Bridging Knowledge Gaps: RAG addresses a critical need in AI applications - the ability to access and incorporate specific, up-to-date information that LLMs might not have been trained on. This capability is essential in fields where precision and current knowledge are paramount.
Versatility Across Domains: The adaptability of RAG to various industries, from healthcare and finance to customer service and legal, has contributed to its widespread acceptance. Its ability to tailor responses based on domain-specific data makes it invaluable in diverse applications.
Enhancing LLMs with Real-Time Data
Dynamic Data Integration: RAG allows LLMs to dynamically integrate real-time data, ensuring that the responses are not only accurate but also reflect the latest developments and information.
Improving Response Quality: By augmenting LLMs with external data, RAG significantly improves the quality and relevance of their responses, making them more useful and reliable for users.
Adoption in AI Development
Standard in AI Toolkits: RAG has become a standard component in the toolkits of AI developers. Its ability to enhance the functionality of LLMs has made it a go-to solution for improving AI interactions and outputs.
Innovation in AI Research: The adoption of RAG is also evident in AI research, where it is being used to explore new frontiers in machine learning and natural language understanding.
Industry Applications
Customer Service and Support: In customer service, RAG-equipped chatbots provide more accurate and contextually relevant answers, leading to better customer experiences.
Content Creation and Analysis: In media and content creation, RAG is used to generate more informed and comprehensive content, drawing on a wide range of current sources.
Future Implications
Setting New Standards in AI: The widespread adoption of RAG is setting new standards in AI, particularly in how LLMs are developed and utilized. It is pushing the boundaries of what AI systems can achieve in terms of accuracy, relevance, and adaptability.
Driving Further Innovations: As RAG becomes an industry standard, it is likely to drive further innovations in AI, leading to even more advanced and sophisticated AI applications.
Advanced Insights and Decision-Making with RAG
Retrieval-Augmented Generation (RAG) has become a pivotal tool in the realm of artificial intelligence, offering advanced insights and enhancing decision-making processes across various industries. By integrating external data sources into Large Language Models (LLMs), RAG provides a depth and breadth of knowledge that was previously unattainable. Let's explore how RAG is revolutionizing insights and decision-making.
When Should I Use RAG and When Should I Fine-Tune the Model?
In the evolving landscape of artificial intelligence, understanding when to employ Retrieval-Augmented Generation (RAG) versus when to fine-tune a model is crucial for optimizing the performance of Large Language Models (LLMs). Both strategies have their unique applications and benefits, and choosing the right approach depends on the specific requirements of your AI project.
Using Retrieval-Augmented Generation (RAG)
Dynamic Data Integration: RAG is ideal when your application requires integrating dynamic, real-time data from external sources. It's particularly useful in scenarios where the information is rapidly changing or where the model needs to access the latest data that wasn't available during its initial training.
Broadening Knowledge Base: Use RAG when you need to broaden the knowledge base of your LLM beyond its training data. This is especially relevant for applications that require up-to-date information or domain-specific knowledge that the model was not originally trained on.
Enhancing Accuracy and Relevance: RAG should be your go-to option when the goal is to enhance the accuracy and relevance of responses, especially in cases where providing current and context-specific information is crucial.
Cost-Effective Solution: Opt for RAG when you need a cost-effective solution that doesn't require extensive retraining of the model. RAG can be a more efficient choice in terms of computational resources and time.
Fine-Tuning the Model
Specific Task or Domain Adaptation: Fine-tuning is the preferred approach when you need the model to adapt to a specific task or domain. This involves retraining the model on a dataset that is tailored to your specific use case, allowing the model to learn the nuances and intricacies of that particular domain.
Customizing Model Behavior: If you need to alter the model's behavior or output style to suit specific requirements, fine-tuning is the way to go. This process adjusts the model to generate responses that align more closely with your desired outcome.
Dealing with Unique Data Sets: In cases where you have unique data sets that are not publicly available or are highly specialized, fine-tuning the model on this data can lead to better performance compared to using a general-purpose model.
When RAG is Insufficient: There are scenarios where RAG alone might not be sufficient, especially when the model needs to deeply understand and generate content in a specialized manner. In such cases, fine-tuning the model with specialized data is necessary.
Combining RAG and Fine-Tuning
Hybrid Approach for Enhanced Performance: In many cases, a hybrid approach that combines RAG with fine-tuning can yield the best results. You can use RAG to augment the model's knowledge base with real-time data while fine-tuning it on specific datasets to tailor its understanding and output to your domain.
Customizing LLM with Data: Options and Best Methods (Prompt Engineering vs. RAG vs. Fine-Tune vs. Pretrain)
Customizing Large Language Models (LLMs) to suit specific needs and applications is a crucial aspect of AI development. Various methods like Prompt Engineering, Retrieval-Augmented Generation (RAG), Fine-Tuning, and retaining offer unique ways to tailor LLMs. Understanding these methods and their best use cases is essential for effective customization.
Prompt Engineering
Definition: Prompt Engineering involves crafting specialized prompts to guide the behavior of LLMs. It's a way of interacting with the model to elicit specific types of responses.
Use Case: Best for quick, on-the-fly guidance of LLMs where you need to extract specific information or responses without altering the underlying model.
Advantages: It's fast, cost-effective, and doesn't require any training. Ideal for applications where the model's base knowledge is sufficient, but specific responses are needed.
Retrieval-Augmented Generation (RAG)
Definition: RAG combines an LLM with external knowledge retrieval, dynamically pulling in relevant information from external sources to enhance the model's responses.
Use Case: Suitable for applications requiring up-to-date information or domain-specific knowledge that the LLM was not originally trained on.
Advantages: Enhances the accuracy and relevance of responses by supplementing the LLM's knowledge base with real-time data. It's particularly effective in scenarios where information is rapidly evolving.
Fine-Tuning
Definition: Fine-tuning involves adapting a pre-trained LLM to specific datasets or domains. It's a process of retraining the model on a new dataset to refine its responses.
Use Case: Ideal for domain or task specialization where the model needs to understand and generate content that is highly specific to a particular field or type of task.
Advantages: Offers granular control and high specialization. It allows the model to deeply understand the nuances of specific data sets.
Pretraining
Definition: Pretraining is the process of training an LLM from scratch on a unique dataset. It's used to create models tailored for specific needs or domain-specific corpora.
Use Case: Necessary when existing models do not cover the specific domain or task, or when highly specialized knowledge is required.
Advantages: Provides maximum control and is tailored for specific needs. It's the go-to method for developing models with unique capabilities not covered by existing pre-trained models.
Choosing the Best Method
Consider Your Data and Requirements: The choice among these methods depends largely on the nature of your data and the specific requirements of your application.
Combining Methods for Optimal Results: Often, a combination of these methods can be used. For instance, you might fine-tune a model for a specific domain and then use prompt engineering for specific queries.
Resource Availability: Consider the resources available, including time, computational power, and data. Fine-tuning and pretraining require significant resources compared to prompt engineering and RAG.
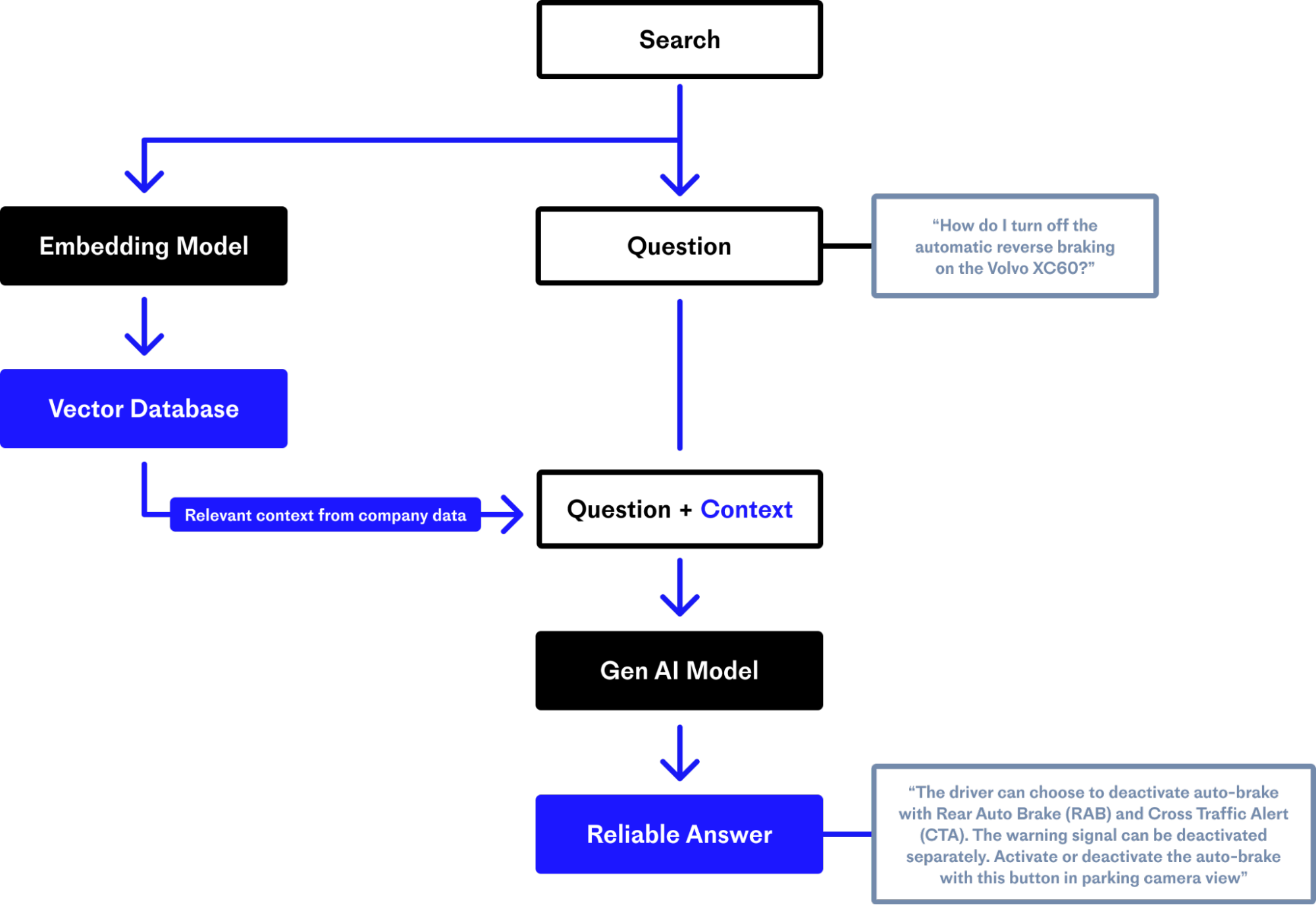
What is a Reference Architecture for RAG Applications?
A reference architecture for Retrieval-Augmented Generation (RAG) applications serves as a blueprint for designing and implementing systems that leverage this advanced AI technique. It outlines the key components and processes involved in integrating RAG into various applications, ensuring that they efficiently utilize external data sources to enhance the capabilities of Large Language Models (LLMs). Let's delve into the essential elements of a reference architecture for RAG applications.
Core Components of RAG Reference Architecture
Data Preparation and Indexing:
Data Collection: Gather and preprocess relevant data from various sources, including databases, online repositories, and other digital platforms.
Indexing: Index this data to facilitate efficient retrieval. This involves organizing the data in a way that makes it easily searchable and accessible for the RAG system.
Integration with Vector Databases:
Vector Search Index: Utilize vector databases for fast and efficient similarity searches. These databases store data in a format that allows for quick retrieval of information based on the query context.
Embedding Models: Implement embedding models to convert text data into numerical vectors, which can then be indexed and stored in the vector database.
Query Processing and Data Retrieval:
Query Interpretation: Develop mechanisms to interpret user queries and transform them into a format that can be used to search the vector database.
Retrieval Mechanism: Create a retrieval system that fetches the most relevant data based on the query's context and the indexed information.
Integration with LLMs:
Data Synthesis: Integrate the retrieved data with the LLM, allowing it to synthesize this information with its pre-existing knowledge base.
Response Generation: Enable the LLM to generate responses that are not only based on its training data but also enriched with the latest, contextually relevant information from the retrieved data.
User Interface and Application Integration:
Application-Specific Interfaces: Design user interfaces and application integrations that allow end-users to interact with the RAG-enhanced LLM seamlessly.
Feedback Loops: Implement feedback mechanisms to continually improve the accuracy and relevance of the responses based on user interactions.
Scalability and Performance Optimization:
Scalable Architecture: Ensure that the architecture can handle increasing volumes of data and user queries without significant performance degradation.
Optimization: Continuously monitor and optimize the system for speed, accuracy, and efficiency.
Best Practices in RAG Reference Architecture
Modular Design: Adopt a modular approach to the architecture, allowing for easy updates and integration of new components.
Data Security and Privacy: Incorporate robust data security and privacy measures, especially when dealing with sensitive or personal information.
Continuous Learning and Adaptation: Design the system to learn from user interactions and adapt over time, improving its accuracy and effectiveness.
The Future and Evolution of RAG
The trajectory of Retrieval-Augmented Generation (RAG) in the field of artificial intelligence is on a remarkable ascent, promising a future where AI systems are not only more intelligent but also more attuned to the nuances of human knowledge and interaction. As we look ahead, the evolution of RAG is set to redefine the capabilities of Large Language Models (LLMs) and their applications across various sectors.
Advancements in AI Integration
Seamless Integration with Emerging AI Technologies: Future developments in RAG are expected to focus on its seamless integration with other cutting-edge AI technologies. This integration will enhance the capabilities of AI systems, making them more versatile and efficient in processing and understanding complex data.
Synergy with IoT and Real-Time Analytics: The convergence of RAG with IoT (Internet of Things) and real-time analytics will open new frontiers in AI applications. This integration will enable AI systems to process and analyze data from a myriad of sources in real-time, leading to more dynamic and responsive AI solutions.
Enhancing Personalization and Contextual Relevance
Deep Personalization: As RAG evolves, it will offer more profound personalization in AI interactions. AI systems will be able to understand and adapt to individual user preferences and contexts, providing more tailored and relevant responses.
Contextual and Cultural Adaptation: Future iterations of RAG will likely focus on enhancing the contextual and cultural understanding of AI systems. This means AI will become more adept at interpreting and responding to queries with a deep understanding of the user's cultural and contextual background.
Addressing Computational Efficiency
Optimizing Computational Resources: One of the challenges with current RAG implementations is the computational load. Future developments will aim to optimize these systems, making them more efficient and accessible for a broader range of applications.
Refined Data Retrieval Mechanisms: The efficiency and accuracy of the data retrieval process in RAG systems will continue to improve. This will result in faster, more accurate responses, enhancing the overall user experience.
Ethical AI and Responsible Implementation
Focus on Ethical AI: As RAG becomes more prevalent, there will be an increased focus on ethical considerations in AI development. This includes addressing issues related to data privacy, bias in AI responses, and ensuring transparency in AI decision-making processes.
Responsible and Inclusive AI Development: The future of RAG will involve strategies for responsible AI implementation. This includes considering the societal impacts of AI, ensuring equitable access to AI benefits, and developing AI in a way that is inclusive and beneficial to all sections of society.
Expanding Applications Across Industries
Broader Industry Applications: RAG's future will see its expansion into a wider range of industries. From healthcare, where it can provide up-to-date medical information, to finance, where it can offer real-time market analysis, RAG's potential applications are vast.
Innovative Use Cases: As RAG technology matures, we can expect to see innovative use cases emerging. This could range from enhanced educational tools that provide personalized learning experiences to advanced environmental monitoring systems that leverage real-time data for better decision-making.
Conclusion
Retrieval-Augmented Generation represents a significant advancement in the field of AI. By bridging the gap between static knowledge bases and dynamic, real-world information, RAG enhances the intelligence and utility of AI systems. Its role in driving forward the capabilities of LLMs, coupled with its potential for ethical and responsible application, marks RAG as a key player in the future landscape of artificial intelligence. As RAG continues to develop and integrate with other AI technologies, its impact is expected to grow, leading to more sophisticated, efficient, and user-centric AI solutions.